Two short zines about online erotica.
Scraping the Bottom categorizes and analyzes comments scraped from the most popular story on Literotica.
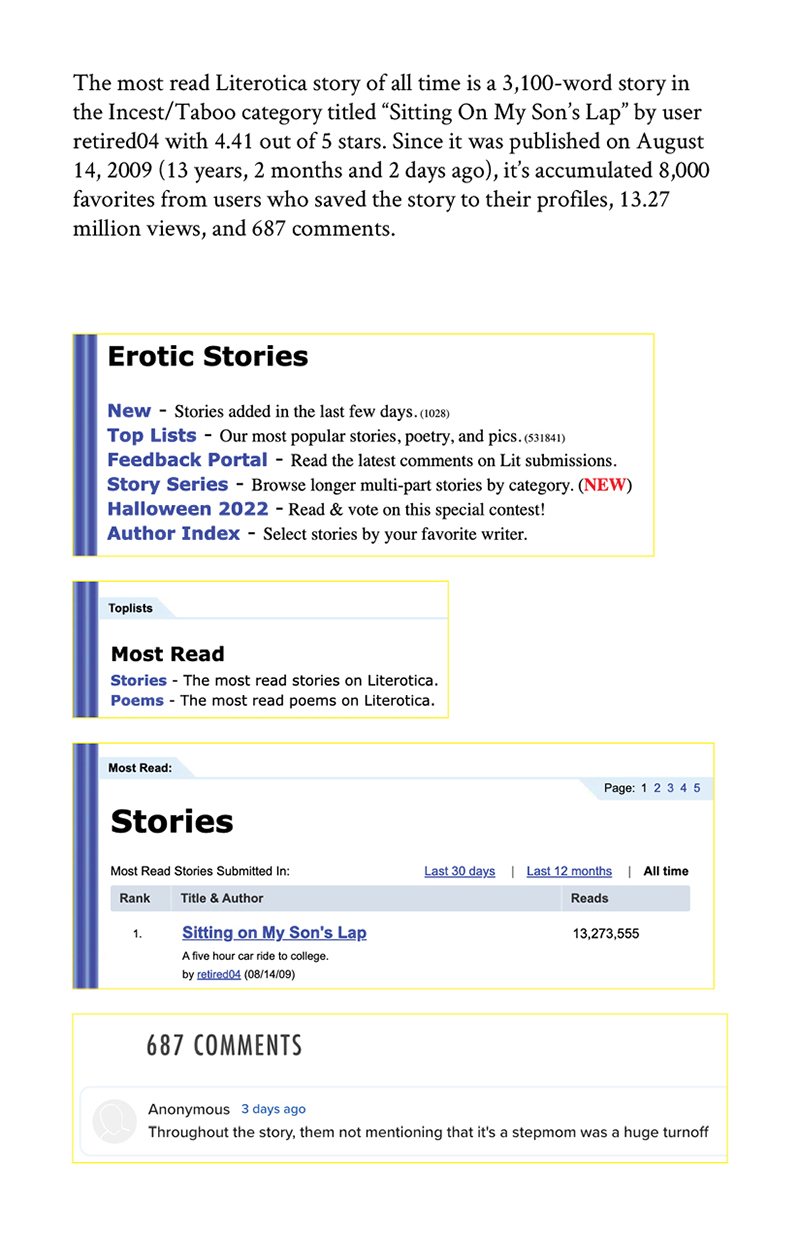
Literotica (a portmanteau of literature and erotica) is a free erotic fiction website launched in 1998, 24 years ago. As of October 2022, amateur authors had contributed half a million stories, and the website was the 492nd most popular in the world. The top story, an incest story titled "Sitting On My Son's Lap," had 13.27 million views and 687 comments.
Why am I so fascinated by this website and the comments?
As an archive, it’s like a steady boulder in an ever-growing river. While the modern web has rushed onwards without it, it still had a homepage design straight out of the 90s and only launched a beta UI in the past few years. Its average visit time is far longer than that of most websites because people are using it to get off. In a way, it lives outside of time.
Film scholar Linda Williams’ concept of the body genre describes a category of text that “focuses on the sensations of its characters’ bodies and aims to elicit a bodily response from its readers, thereby lessening the space between reader and text. [B]ody genres often reduce the action of the story to the vagaries of the bodies inside the stories in an attempt to take hold of the readerly bodies they address and instigate bodily mimicry.” Williams temporally differentiates the ‘body genres’ by associating pornography with being ‘on time’ (situations and bodies aligning perfectly).”
Because these texts correspond so strongly to bodily time and are such a primitive format, descended from the usenet txt, it seems their design and medium doesn’t otherwise have to respond to capitalist time to generate traffic and ad revenue. All the readers need is the story itself, and their reactions—horny, visceral, disgusted, sentimental, nostalgic, fantastic—are so powerful. They’re pressed right up against the text.



Innocence reports on the results of running tentacle porn through IBM Watson analysis, illustrated by DALL-E generations.
IBM Watson “uses deep learning to extract meaning and metadata from unstructured text data" from the legal, financial, and media industries. It’s been used to create a COVID-19 incident map and a comprehensive world law search engine.
I asked it to read some tentacle porn, to see what happens when a professional tool encounters and processes an embodied, intimate text in a state of innocence. These are its findings.

